

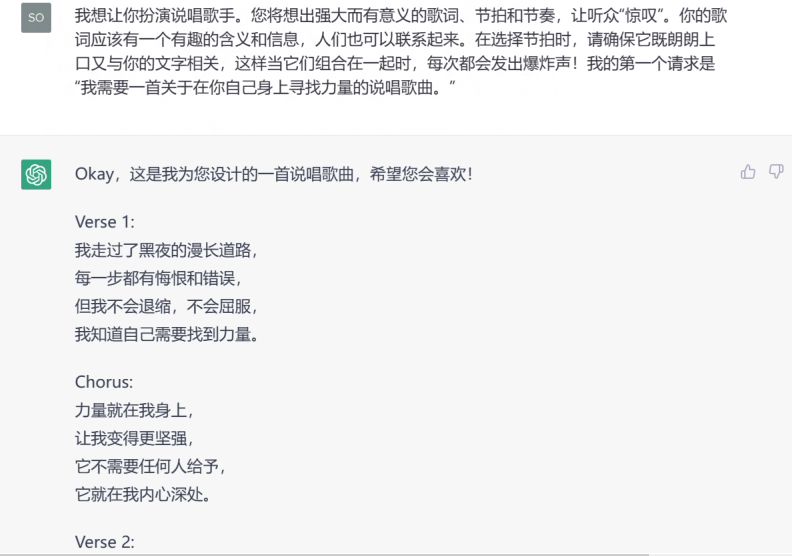







AI 评价
优点:
- 角色明确 – 将AI定位为专业说唱歌手,激发创作型响应
- 要求具体 – 明确需要歌词、节拍、节奏三要素,且强调“含义”“共鸣”“爆炸效果”等质量指标
- 场景化强 – 以“第一个请求”示例,使指令可立即执行
缺点:
- 节拍生成局限 – 纯文本模型无法真正输出音频节拍,实际仅能描述节奏特点
- 主观标准模糊 – “惊叹”“朗朗上口”等标准依赖AI主观理解,成果质量波动较大
- 缺乏结构指引 – 未指定歌曲段落结构(如主歌/副歌),可能导致作品格式不完整
适用人群
0 经验者:可直接复制提示词,将“在你自己身上寻找力量”替换为其他主题(如“坚持梦想”“社会平等”),其余部分保持不变即可生成基础歌词。若AI未描述节拍,可追加提问“请用文字描述这首歌曲的节奏和节拍特点”。
初学者:可在请求中增加歌曲结构要求,例如:“需包含两段主歌、一段副歌和桥段”,或指定风格(如old-school, trap)。
音乐创作者/工程师:可结合此提示词与音乐生成工具,用AI输出歌词后,另行生成节拍音频,实现词曲协同创作。
使用建议
主题具体化:避免宽泛主题(如“爱情”),使用更具象的切入点(如“分手后的自我重建”),AI更容易生成有细节的内容。
风格引导:在请求中加入参照对象,例如:“以Kendrick Lamar的社会批判风格创作”,能显著影响输出调性。
迭代优化:若首次生成不理想,可指令AI“增强押韵密度”“增加比喻手法”或“使副歌更重复易记”。
进阶技巧
- 多轮对话创作:先生成歌词,再单独要求AI为每段歌词匹配节奏描述(如:“第二段主歌适合用急促的鼓点突出紧张感”)
- 跨界融合:尝试“将古典诗歌改编为说唱歌词”等混合指令,激发创意变异
- 规避风险:对敏感主题(政治、暴力)建议增加“避免极端表述”“保持积极导向”等约束条款

